Розпізнавання накладних з паперових документів
Стаття в розробці, пишу факультативно в паузах між задачами.
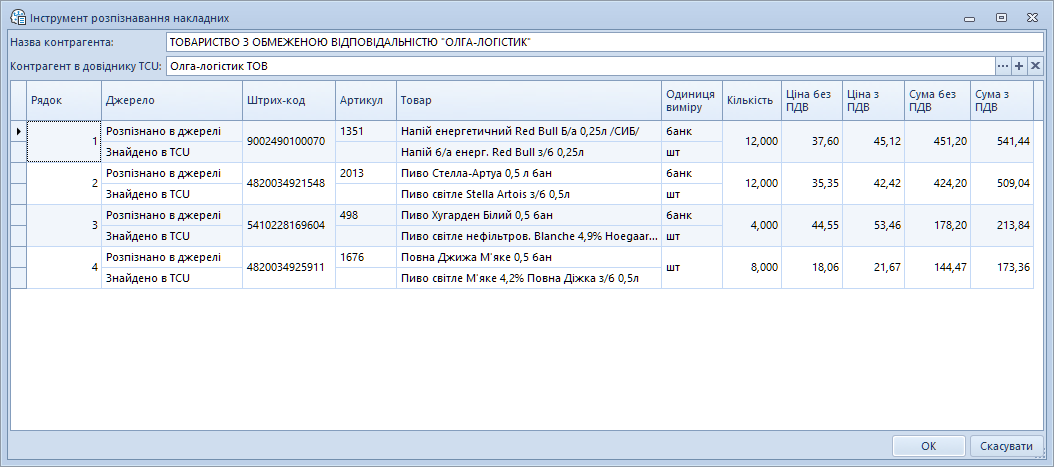
Введення накладних від постачальників вимагає багато часу, уваги та зусиль. Це і сама процедура введення даних, так і перевірка коректності.
Накладні від постачальників надходять у різному вигляді. Ідеально, коли постачальник притримується узгодженого формату, і процес імпорту такого документа максимально автоматизований - по натисканню однієї кнопки.
Але постачальників багато різних, і в реальному житті ми можемо спостерігати цілий спектр різних варіантів надходження документів - від узгодженого формату, де імпорт максимально автоматизований, до паперової накладної, в якій інформація вписана від руки не дуже розбірливим почерком.
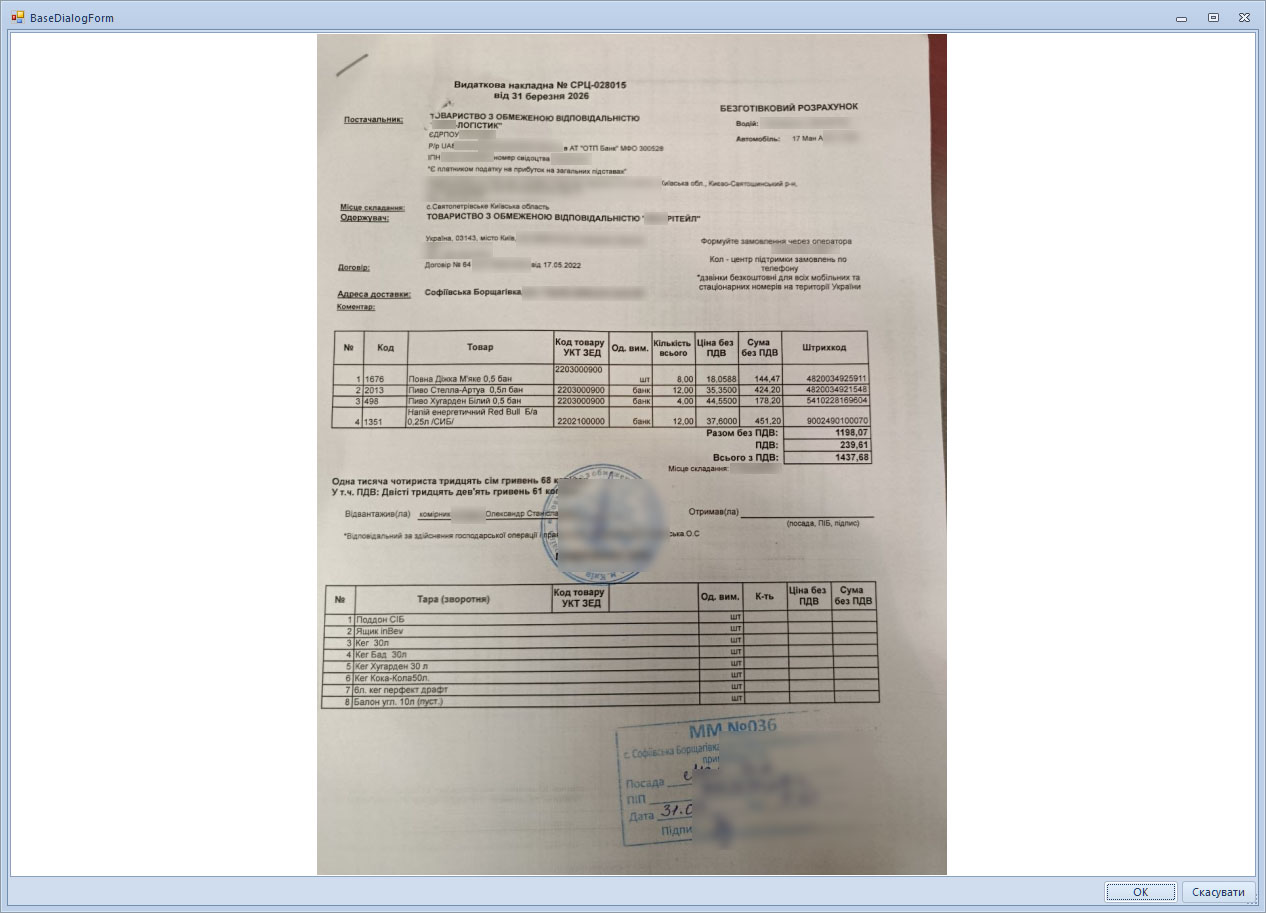
Варіант "від руки" є, звичайно, крайнім, але до сих пір паперова накладна привезена разом з товаром є доволі розповсюдженим варіантом. І якщо з Excel-варіантом можна якось жити - написати майстер імпорту, навчити його типовим макетам від різних постачальників (бо структура документа в різних постачальників може відрізнятись - різний формат шапки, різна послідовність та набір колонок в переліку товарів), то з паперовоми накладними складність задачі зростає на декілька порядків.
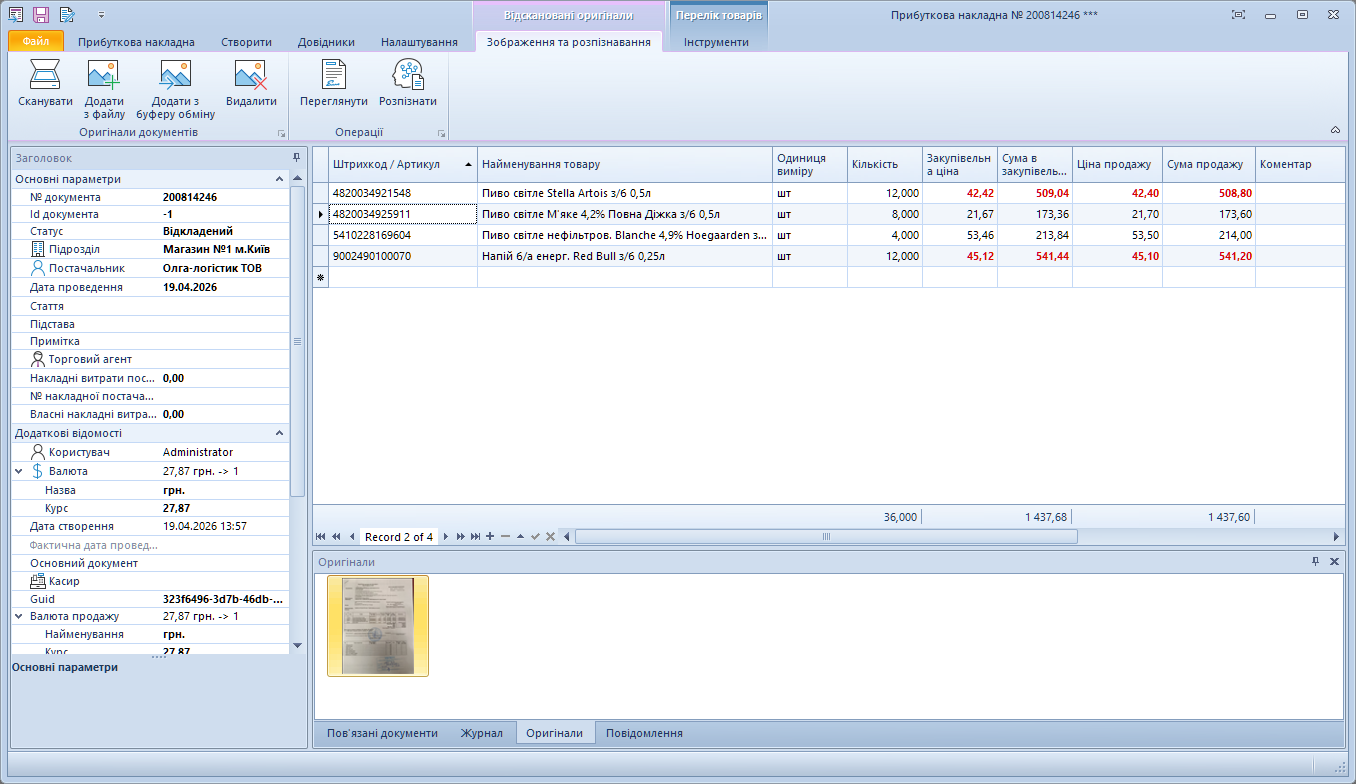
Є системи розпізнавання тексту, вони ж OCR. Той самий Fine Reader, якому вже 30 років. Він непогано розпізнає книжковий текст. Все стає гірше, коли це структурований документ із зонами та таблицями. Все стає ще гірше, коли такий документ погано роздрукований (зношений барабан лазерного принтера - знаменита вертикальна бокова смуга; або забиті дюзи струменевого принтера, коли текст виглядає як строчна розгортка старого кінескопа). Все стає ще гірше, коли таку накладну сфотографують дешевим китайським телефоном, де ми додатково отримаємо розмите сіре шумне зображення.
Програми нормальні, алгоритмичні, перед такими задачами пасують. Але ж людина якось це спроможна прочитати. Тобто, інформації в документі для цього достатньо?
Ні. Недостатньо. Просто людина володіє набагато більшим обсягом інформації, порівняно з тим, що бачить в документі. Людина розуміє контекст - це накладна (це не просто слово, це сутність, за якою стоїть певний функціонал, певне призначення, певні функції), в ній є постачальник (це теж не просто слово, це юридична особа, який постачає товар, що таке юридична особа - це теж сутність зі своїм величезним інформаційним контекстом), є товари, в товарів є назви та артикули, в товарів є кількості та ціни. Людина бачила вже багато подібних накладних. Словарний запас, життєвий досвід і т.д. Тобто користуючісь додатковим величезним обсягом інформації, відсутню в документі інформацію можна додати, значно розширити контекст. Саме в цьому і полягає принципова ключова різниця між програмою (яка працює з обмеженим обсягом інформації), та людиною (обсяг інормації в якої, і, відповідно, контекст, є величезним).
Поки комп'ютери оперували класичними програмами (ті, що реалізують звичайні, детерміновані, чітко визначені алгоритми), людина у вирішенні подібних задач мала абсолютну перевагу. Не можна сказати, що впродовж минулих епох не було пошуку напрямків вирішення такого класу задач. Але всі вони стикались із двома проблемами - нестачею обчислювальних ресурсів та обмеженим обсягом інформації.
Для прикладу, подивимось, як ці проблеми ставились майже 40 років тому.


Мені було 16 років, коли я отримав цей журнал, і вперше детально ознайомився з проблематикою (подібні матеріали тоді знаходились в жорсткому дефіціті, і будь які статті на комп'ютерну тему зачитувались "до дірок"). Зараз, коли знову почали обговорювати тему штучного інтелекту з кожної праски, в мене майнула та сама класична думка "Це ж було вже!". Звичайно, радянська наука була повністю вторинна відносно американської. І вся ця проблематика, озвучена радянським "професором" була вже тоді добре відомою в передових державах. Але все одно раджу почитати. Це цікаво відносно сучасного стану речей.
І хоча в статті робиться висновок, що все це справи далекого майбутнього, на сучасному рівні їх вже можна вирішувати. Або далеке майбутнє вже наступило?
Інтернет, який надав астрономічний обсяг інформації, та графічні процесори, які раптом виявились найбільш архітектурно вдалими для паралельних обробок, забезпечили якісний стрибок. Як результат - поява LLM (навчені мовні моделі), які почали розуміти контекст в самому широкому сенсі, і окрім розпізнавання літер, оперують сенсами та сутностями. І саме тут ми маємо ключ для вирішення подібних задач.
Andriy Kravchenko
Admin, Writer, File Uploader
Останнє оновлення:
5/16/2026 5:08:58 PM
489