Розробка AI-помічника для сайту
Розробка AndriyCo.AI.SiteAssistant починалась як практична задача: створити AI-помічника для сайту, який міг би відповідати на запитання користувачів не “загальними знаннями”, а на основі конкретних матеріалів сайту — статей, інструкцій, сторінок підтримки та інших документів. По суті, це мав бути вбудований консультант, який відкривається на сайті через віджет, приймає запитання користувача, знаходить релевантні матеріали у власній базі знань і формує відповідь із посиланнями на джерела.
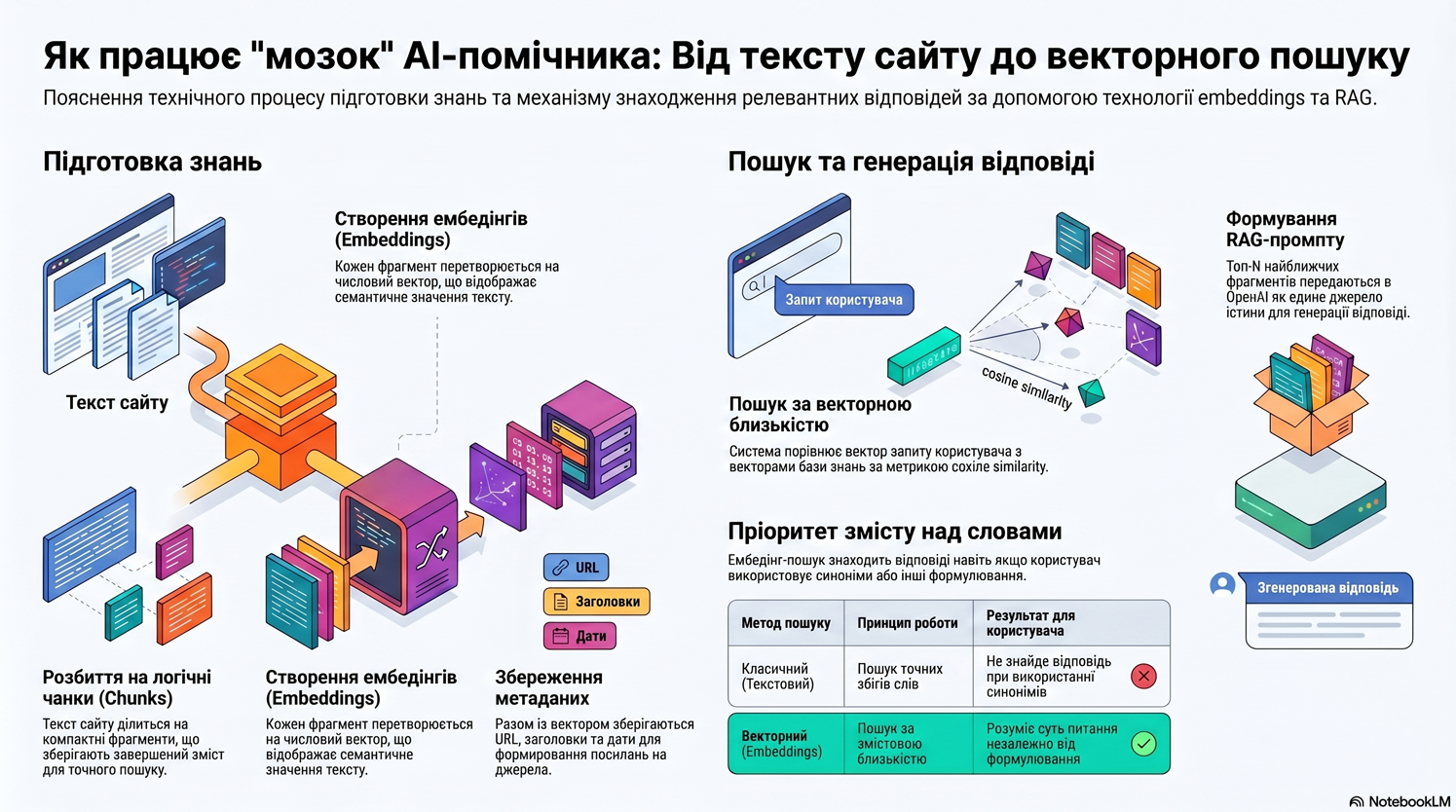
На перший погляд така система виглядає досить прямолінійною. Є сайт, є набір статей, є OpenAI API, є embeddings, є чат. Але в процесі розробки швидко стало зрозуміло, що найбільші складнощі виникають не там, де їх зазвичай очікуєш. Сам пошук релевантних фрагментів, генерація відповіді, збереження діалогу, JavaScript-віджет, SignalR-повідомлення, автопосилання, оформлення проміжних відповідей — усе це важливі частини системи, але вони мають досить зрозумілу технічну природу. Найцікавішою і найскладнішою виявилась інша проблема: як правильно працювати з контекстом діалогу, коли користувач різко змінює тему.
Загальна ідея проекту
AndriyCo.AI.SiteAssistant будується як conversation-aware RAG-система. Це означає, що відповідь формується не лише на основі поточного запитання користувача, а й з урахуванням попереднього діалогу. Такий підхід потрібен, тому що в реальному чаті користувачі рідко формулюють кожне запитання повністю незалежно.
Наприклад, після запитання “Як налаштувати бонуси?” користувач може запитати: “А як їх списати?” або “А де це знаходиться в Trade Control Center?”. Без контексту система не завжди зрозуміє, про які саме бонуси йдеться. Тому історія діалогу або короткий summary попередньої розмови дійсно допомагає зробити відповіді більш природними.
Базовий сценарій роботи виглядає так:
- Користувач ставить запитання у віджеті на сайті.
- Система бере поточне запитання і, за потреби, summary попереднього діалогу.
- Для запитання будується embedding.
- За embedding виконується пошук найбільш релевантних фрагментів у базі знань.
- У prompt передаються знайдені фрагменти, контекст діалогу і саме запитання.
- Модель формує відповідь, використовуючи лише надані матеріали.
- Відповідь зберігається в історії чату і повертається користувачу через віджет.
Така архітектура дозволяє зробити помічника не просто “чатом з AI”, а саме консультантом по конкретному сайту або продукту.
Віджет і зовнішній вигляд відповіді
Окрема частина роботи стосувалась клієнтського віджета. Його планувалося зробити універсальним JavaScript-компонентом, який можна підключати до будь-якого сайту. Віджет має виглядати як типовий AI-помічник: кнопка в правому нижньому куті, панель чату, історія повідомлень, поле введення, кнопка очищення діалогу.
Під час роботи над віджетом з’явилось кілька практичних нюансів. Наприклад, проміжні повідомлення, які приходять через SignalR, потрібно було візуально відрізняти від фінальних відповідей. Ми зупинились на ідеї робити їх менш насиченими, більш сірими, щоб користувач розумів: це ще не остаточна відповідь, а проміжний стан обробки.
Інший нюанс — автоматичне перетворення URL у клікабельні посилання. Це корисно, коли відповідь містить посилання на статті або сторінки підтримки. Але виникла проблема: одне й те саме посилання могло повторюватися кілька разів. Спочатку можна було б прибирати дублікати на клієнті, у JavaScript-обробнику, але більш правильним рішенням стало прибрати повтори на сервері. Причина проста: сервер є єдиним джерелом якості відповіді. Якщо в майбутньому з’являться інші клієнти — Telegram-бот, Viber-бот, мобільний застосунок або інший веб-віджет — кожен із них не повинен заново реалізовувати логіку очищення дубльованих посилань.
Цей підхід добре показує загальний принцип проекту: усе, що стосується змісту, якості відповіді та її структури, бажано вирішувати на сервері. Клієнт має відповідати переважно за відображення.
Імпорт матеріалів і база знань
Щоб AI-помічник міг відповідати на запитання, йому потрібна база знань. Для цього в проекті реалізовувався механізм імпорту сторінок сайту. Одним із прикладів був імпорт матеріалів з base2base.ua.
Для імпорту важливо не просто завантажити HTML-сторінку. Потрібно отримати зміст, видалити зайві елементи, перетворити його у придатний для пошуку текст, розбити на фрагменти і зберегти ці фрагменти разом з embedding. Окремо треба зберігати метадані: URL, заголовок, опис, дату зміни, тип документа, мову.
У процесі роботи також виникла потреба керувати імпортом через інтерфейс. Наприклад, при натисканні кнопки “Імпортувати base2base.ua” доцільно не запускати одразу жорстко заданий процес, а показувати діалог. У цьому діалозі можна вказати адресу сторінки, чи потрібна рекурсія, і максимальну кількість сторінок для імпорту. За замовчуванням можна підставляти адресу https://base2base.ua, рекурсію вмикати, а кількість сторінок брати з поточної логіки імпорту.
Тобто проект поступово переходив від простого тестового імпорту до більш керованої системи наповнення бази знань.
Підготовка бази знань: chunks та embeddings
Окремо важливо описати, як саме матеріали сайту готуються для подальших відповідей. AI-помічник не може кожного разу відправляти в OpenAI весь сайт або навіть повний текст усіх статей. Це було б занадто дорого, повільно і технічно неефективно. Тому матеріали попередньо перетворюються у базу знань, придатну для швидкого пошуку.
Після імпорту сторінки система отримує її HTML і виділяє з нього корисний текстовий зміст. Зайві елементи сторінки — меню, футер, технічні блоки, службова навігація — не повинні потрапляти в основний текст знань, бо вони погіршують якість пошуку. Для AI-помічника важливо зберігати саме той зміст, який може бути використаний у відповіді: назву статті, опис, основний текст, важливі підзаголовки, інструкції, пояснення, посилання.
Далі текст документа розбивається на невеликі фрагменти — chunks. Це один із ключових етапів. Якщо chunk занадто великий, він міститиме багато зайвої інформації, і його буде складніше точно зіставити із запитанням користувача. Якщо chunk занадто малий, він може втратити контекст: наприклад, окреме речення може бути незрозумілим без попереднього абзацу або заголовка.
Тому chunk має бути достатньо компактним для точного пошуку, але достатньо змістовним для відповіді. Важливо також не розривати текст посеред слова або в невдалому місці. Краще розбивати матеріал по абзацах, реченнях або логічних блоках статті. У такому випадку кожен chunk зберігає завершений зміст і може бути використаний як джерело для відповіді.
Для кожного chunk система будує embedding — числовий вектор, який відображає зміст цього фрагмента. Якщо говорити спрощено, embedding перетворює текст на набір чисел таким чином, що схожі за змістом тексти отримують близькі вектори. Наприклад, фрагменти про “нарахування бонусів”, “бонусну програму” і “накопичення бонусів клієнтом” можуть бути близькими у векторному просторі, навіть якщо в них не збігаються всі слова буквально.
Разом із embedding зберігаються й метадані chunk: ідентифікатор документа, URL сторінки, заголовок, тип документа, мова, порядковий номер фрагмента, можливо — дата останньої зміни. Це потрібно не тільки для пошуку, а й для формування джерел відповіді. Коли помічник відповідає користувачу, бажано показати, з яких сторінок або статей була взята інформація.
Як запит користувача знаходить потрібні фрагменти
Коли користувач ставить запитання, система виконує схожий процес, але вже для самого запиту. Поточне запитання користувача перетворюється на embedding. Після цього цей embedding порівнюється з embeddings усіх або відібраних chunks у базі знань.
Пошук виконується за принципом векторної близькості. Тобто система шукає ті chunks, вектори яких найближчі до вектора запитання. Найчастіше для цього використовують cosine similarity або іншу близьку метрику. Сенс у тому, що порівнюються не просто слова, а змістова близькість текстів.
Це принципово важливо. Звичайний текстовий пошук добре працює, коли користувач використовує ті самі слова, що й у статті. Але реальний користувач часто формулює питання інакше. Наприклад, у статті може бути написано “списання бонусів”, а користувач запитає: “як покупець може використати накопичені бали?”. Для класичного пошуку це можуть бути різні формулювання. Для embedding-пошуку вони можуть бути достатньо близькими за змістом.
Після розрахунку близькості система вибирає кілька найкращих chunks. Саме ці фрагменти і вважаються потенційно релевантними джерелами для відповіді. Зазвичай у prompt передаються не всі знайдені фрагменти, а тільки top N — наприклад, кілька найбільш близьких за змістом. Це дозволяє не перевантажувати модель зайвим текстом і одночасно дати їй достатньо матеріалу для якісної відповіді.
Далі формується фінальний prompt для OpenAI. У нього входять:
- Системна інструкція, яка пояснює моделі, що потрібно відповідати тільки на основі наданих матеріалів.
- ConversationSummary — короткий зміст попереднього діалогу, якщо він доречний.
- Поточне запитання користувача.
- Знайдені chunks із бази знань.
- Додаткові вимоги до відповіді: стиль, мова, формат, необхідність додавати посилання на джерела.
Таким чином OpenAI не “згадує” інформацію про продукт із власних загальних знань, а отримує потрібні матеріали безпосередньо в prompt. Модель у цьому випадку виконує роль інтелектуального редактора і пояснювача: вона бере знайдені фрагменти, зіставляє їх із запитанням користувача і формує зрозумілу відповідь.
Саме ця схема і є основою RAG-підходу: Retrieval-Augmented Generation. Спочатку система знаходить релевантні матеріали у власній базі знань, а вже потім модель генерує відповідь на їхній основі. Це дозволяє поєднати переваги пошуку по власних документах і природної мовної відповіді від OpenAI.
Для AndriyCo.AI.SiteAssistant це особливо важливо, тому що помічник має відповідати не абстрактно, а по конкретних матеріалах сайту. Якщо на сайті є стаття про бонуси, касову програму, імпорт товарів або налаштування Trade Control Center, то відповідь повинна спиратися саме на цю статтю. Якщо ж у базі знань немає відповідного матеріалу, система не повинна вигадувати відповідь, а має чесно повідомити, що в наданих матеріалах недостатньо інформації.
Цей механізм також пояснює, чому проблема зсуву контексту виявилась такою важливою. Пошук chunks залежить від того, як система розуміє поточне запитання. Якщо до нового запитання додати старий ConversationSummary, embedding-пошук і prompt можуть зміститися в бік попередньої теми. Тоді навіть якісна база знань не гарантує правильної відповіді, бо вхідний контекст уже спотворений. Саме тому правильне керування summary і фіксація context shift стали однією з ключових частин проекту.
Чому контекст діалогу одночасно корисний і небезпечний
Наявність контексту — це сильна сторона чат-бота. Але саме вона створила одну з головних проблем.
Коли користувач продовжує одну й ту саму тему, summary попереднього діалогу допомагає. Але коли користувач різко змінює тему, цей summary починає заважати. Система може “триматися” за попередню тему, хоча нове запитання вже стосується зовсім іншого матеріалу.
У RAG-системах це особливо помітно. Адже пошук релевантних фрагментів і формування prompt залежать не лише від поточного запитання, а й від контексту. Якщо контекст містить стару тему, модель може сприйняти нове запитання як продовження попередньої розмови. У результаті вона або шукає не ті матеріали, або отримує релевантні матеріали, але інтерпретує їх крізь старий контекст.
На практиці це проявлялося так: користувач ставив нове запитання, а система відповідала фразою на кшталт “У наданих матеріалах немає достатньо інформації...”. При цьому, якщо те саме запитання відправити без summary попереднього діалогу, відповідь формувалась нормально.
Це був важливий діагностичний момент. Він показав, що проблема не в базі знань, не в embeddings і не в самих матеріалах. Проблема саме в тому, що старий діалоговий контекст іноді заважає новому запитанню.
Перше робоче рішення: повторний запит без ConversationSummary
Після аналізу ситуації було знайдено простий і доволі ефективний механізм. Якщо система отримує відповідь з ознакою недостатності інформації, наприклад відповідь починається з фрази “У наданих матеріалах немає достатньо інформації...”, це можна трактувати як можливий context shift — зміну теми діалогу.
У такому випадку система повторно відправляє те саме запитання, але вже з порожнім ConversationSummary. Тобто вона тимчасово відкидає попередній діалог і дає моделі можливість відповісти тільки на основі нового запитання і знайдених для нього фрагментів.
Це рішення добре спрацювало для поточного запиту. Якщо проблема була саме у старому summary, повторний запит без нього дозволяв отримати нормальну відповідь.
Але після цього з’явилась наступна проблема.
Чому простого повторного запиту було недостатньо
Повторний запит без ConversationSummary вирішував проблему лише для одного конкретного повідомлення. Але історія діалогу при цьому залишалась старою.
Наступного разу, коли користувач ставив нове запитання, система знову формувала ConversationSummary на основі всієї історії: і старих запитань-відповідей до зміни теми, і нових повідомлень після зміни теми. У результаті старий контекст знову повертався в prompt.
Тобто виникав замкнений цикл:
- Користувач змінює тему.
- Система помилково враховує старий контекст.
- Модель відповідає, що в матеріалах недостатньо інформації.
- Система повторює запит без summary і отримує нормальну відповідь.
- Але при наступному запитанні summary знову будується по всій історії.
- Старий контекст знову заважає.
Стало зрозуміло, що потрібно не просто одноразово ігнорувати ConversationSummary. Потрібно зафіксувати сам факт зміни контексту в історії діалогу.
Фінальне рішення: WhenContextShifted в AssistantChatRecord
Найбільш вдалим рішенням стало додати до AssistantChatRecord спеціальну ознаку зміни контексту:
Це поле означає, що на цьому місці в історії діалогу відбувся зсув контексту. Воно nullable, тому для звичайних повідомлень залишається порожнім. Якщо ж система визначила, що попередній summary заважає відповіді, і успішно отримала відповідь після повторного запиту без ConversationSummary, відповідний запис можна позначити як точку зміни контексту.
Після цього логіка формування summary стає значно чистішою. Перед побудовою ConversationSummary система шукає останній запис, у якого WhenContextShifted не дорівнює null. Якщо такий запис є, summary формується тільки з повідомлень після цієї точки. Якщо такого запису немає, summary формується з початку діалогу.
Іншими словами, історія діалогу не видаляється фізично, але для поточного смислового контексту вона ніби “обрізається” по останньому context shift.
Це рішення виявилось кращим за варіант з окремим прапорцем у розмові, тому що в одному довгому діалозі може бути кілька змін теми. Користувач може спочатку питати про бонуси, потім про імпорт сайту, потім про Telegram-бота, потім знову про структуру віджета. Якщо зберігати лише один загальний стан на рівні розмови, це буде менш гнучко. А якщо фіксувати зсув контексту безпосередньо в записах чату, система отримує природну “лінію часу” зміни тем.
Як працює нова логіка
Фінальна логіка може виглядати так:
- Користувач ставить запитання.
- Система формує ConversationSummary не з усієї історії, а тільки з частини після останнього WhenContextShifted.
- Виконується пошук релевантних фрагментів.
- Модель формує відповідь.
- Якщо відповідь містить ознаку недостатності інформації, система розглядає це як можливий context shift.
- Система повторює запит без ConversationSummary.
- Якщо повторна відповідь стала нормальною, запис позначається через WhenContextShifted.
- Усі наступні summary будуються вже з нової смислової точки діалогу.
Головна перевага такого підходу — він не руйнує історію. Старі повідомлення залишаються в базі. Їх можна показувати користувачу, аналізувати, використовувати для статистики або діагностики. Але вони більше не заважають формуванню відповідей після зміни теми.
Чому це рішення добре підходить саме для AndriyCo.AI.SiteAssistant
AndriyCo.AI.SiteAssistant — це не абстрактний чат без предметної області. Він працює з конкретною базою знань, конкретними статтями і конкретними продуктами. Тому помилка контексту тут особливо небезпечна.
Якщо звичайний AI-чат трохи “потягне” стару тему в нову відповідь, це може виглядати просто як неточність. Але для помічника на сайті підтримки це може означати, що користувач отримає неправильну інструкцію або не отримає відповідь на питання, хоча потрібна стаття насправді є.
Саме тому важливо, щоб система вміла відрізняти продовження теми від її зміни.
Додавання WhenContextShifted добре вписується в архітектуру проекту ще й тому, що це рішення залишається серверним. Воно не залежить від конкретного клієнта. Один і той самий механізм буде працювати для веб-віджета, Telegram-бота, Viber-бота або будь-якого іншого інтерфейсу, який використовуватиме той самий серверний API.
Потенційні покращення детектування context shift
Поточний підхід використовує відповідь моделі з ознакою недостатності інформації як практичний сигнал. Це добре, тому що такий сигнал легко виявити і він уже виникав у реальних сценаріях.
Але в майбутньому механізм можна зробити більш точним. Наприклад, можна додати окрему перевірку схожості між новим запитанням і попереднім summary. Якщо embedding нового запитання дуже далекий від embedding попередньої теми, це може бути додатковим сигналом context shift.
Також можна попросити модель окремо класифікувати запитання: чи є воно продовженням попереднього діалогу, чи це нова тема. Але такий підхід додає ще один виклик до моделі, тобто збільшує вартість і затримку. Тому для першої робочої версії краще мати простішу і контрольовану логіку.
Практичне рішення через WhenContextShifted цінне тим, що воно не вимагає перебудовувати всю архітектуру. Воно просто додає в історію чату точку, від якої треба починати новий смисловий контекст.
Висновок
Розробка AndriyCo.AI.SiteAssistant показала, що створення якісного AI-помічника для сайту — це не лише питання підключення OpenAI API або побудови embeddings. Найважливіші проблеми виникають на межі між технічною логікою і поведінкою реального користувача.
Користувач не завжди веде діалог лінійно. Він може уточнювати попереднє питання, а може раптово перейти до зовсім іншої теми. Для людини така зміна очевидна. Для RAG-системи — ні. Якщо механічно додавати summary попереднього діалогу до кожного запиту, цей summary може з корисного інструмента перетворитися на джерело помилок.
Саме тому одним із ключових результатів роботи над проектом стало рішення явно фіксувати зсув контексту в історії чату через поле WhenContextShifted у AssistantChatRecord. Це дозволяє не втрачати історію, але правильно обмежувати ту її частину, яка використовується для побудови ConversationSummary.
У підсумку система стає більш стійкою. Вона краще поводиться у довгих діалогах, коректніше реагує на зміну теми і не переносить старий смисловий контекст туди, де він уже не потрібен. Для AI-помічника, який має працювати на реальному сайті і відповідати на запитання реальних користувачів, це не дрібна оптимізація, а одна з базових умов якості.
Andriy Kravchenko
Admin, Writer, File Uploader
Останнє оновлення:
5/12/2026 1:52:49 AM
207
Прикріплені файли